En los últimos años la interfaces de usuario para aplicaciones web “ricas”, implementadas con el estándar HTML/CSS/Javascript, han experimentado grandes avances, en detrimento de las tecnologías basadas en plugins, como Flash o los Applets Java. Comenzando, por ejemplo, por el componente Canvas de HTML5, que permite el dibujado 2D a bajo nivel con Javascript, posibilitando la creación de casi cualquier componente de interfaz de usuario sobre el navegador web sin necesidad de plugins. Continuando por la proliferación de potentes frameworks Javascript para animaciones (JQuery, Mootools, Script.aculo.us, etc.), widgets avanzados (JQuery UI, JQuery Mobile) o, incluso, lógica y data-binding (d3.js, backbone.js, AngularJS, etc.), a los cuales se unen nuevos lenguajes de todavía más alto nivel como Coffeescript, Dart o LESS (para CSS). Todo ello conforma uno de los ecosistemas de tecnologías más activo actualmente, clave para los d�iseñadores de interfaces de usuario de las aplicaciones web más impactantes. Pero ¿hay vida más allá de la propia web para HTML/CSS/Javascript? La respuesta es sí.
El primer sector fuera de la Web, es el sector de las interfaces de usuario para dispositivos móviles. El hecho de que los Smartphone, que presentan grandes capacidades a nivel nativo (como localización GPS, cámara de fotos/vídeo, acelerómetro, etc.), se comercialicen sobre tres plataformas muy distintas (Android, iOS, BlackBerry OS y Windows Phone), unido a la necesidad de publicar aplicaciones en las “app store” rápidamente, ha llevado consigo que se busquen soluciones “programa una vez, ejecuta en cualquier parte” (a costa de sacrificar rendimiento). Aquí también se ha abierto camino HTML/CSS/Javascript (p. ej: JQuery Mobile/PhoneGap). ¿Cómo funcionan en general? Básicamente la idea de esta solución consiste en que la API de la plataforma (móvil en este caso) proporcione:
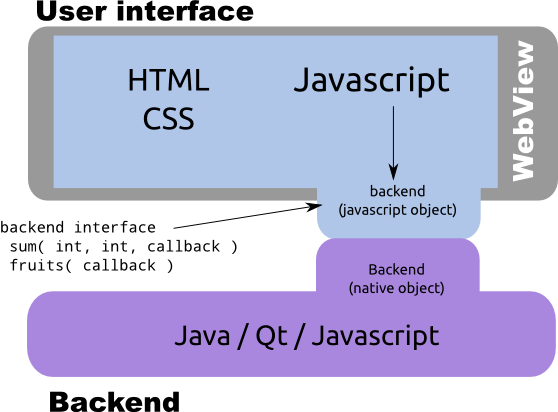
- Un motor de renderizado HTML/CSS/Javascript (es decir, un navegador incrustable), que se suele conocer normalmente desde la API nativa como “WebView” (frecuentemente está implementado con WebKit).
- Una función para “inyectar” objetos nativos y hacerlos visibles como objetos Javascript bajo el nombre de una variable. De esta forma las llamadas desde Javascript al objeto inyectado en Javascript serán atendidas realmente por el objeto nativo.
- Una función para ejecutar código Javascript arbitrario (en forma de cadena de texto, al estilo de la propia eval() de Javascript). De esta forma se pueden llamar a funciones Javascript desde el código nativo.
Un ejemplo paradigmático que explota esta vía es PhoneGap, que amplía la API de Javascript para dar una capa de abstracción multiplataforma sobre las capacidades de los smartphone.
Finalmente, en el campo de las interfaces de usuario para aplicaciones de escritorio, siguen surgiendo y mejorándose multitud de toolkits gráficos para los diferentes lenguajes de programación, muchos de ellos multi-plataforma, o para al menos Windows/Linux/OSX (como Swing, JavaFX, GTK+, Qt, WxWidgets, etc.). Aunque existen aplicaciones que implementan la interfaz de usuario basada en HTML/CSS/Javascript, su uso es menor. En todo caso es posible hacerlo, y en esta entrada se pondran ejemplos de ello (en concreto en Java con el WebView de JavaFX y en C++ con el WebView de Qt).
Ventajas y desventajas
Plantearse la implementación de la interfaz de usuario de un proyecto software empleando HTML/CSS/Javascript, presenta las siguientes ventajas:
- Evita conocer un toolkit gráfico propio del lenguaje de programación sobre el que se vaya a desarrollar el proyecto. La curva de aprendizaje de los toolkits gráficos suele ser elevada, sobre todo si se quiere sacar el máximo provecho.
- Facilita la separación de interfaz de usuario de capas inferiores (lógica y acceso a datos), pudiendo asignar las diferentes partes a programadores especializados en cada parte.
- Facilita la reutilización de la interfaz de usuario, sobre todo en distintas plataformas móviles.
- Facilita encontrar programadores especialistas. La estandarización de estos lenguajes y la proliferación de la Web como plataforma para aplicaciones facilita que exista un gran número de profesionales estén familiarizados con estas tecnologías.
Como desventajas, se podrían destacar:
- Rendimiento. El hecho de que la interfaz de usuario esté implementada con lenguajes de tan alto nivel e interpretados hace que el rendimiento sea inferior a toolkits más cercanos al lenguaje de programación nativo.
- Aspecto “alien”. Las aplicaciones hechas con estas tecnologías difícilmente se adaptan a las guías de estilo de los sistemas operativos.
- Dificultad o imposibilidad de implementar interfaces avanzadas (por ejemplo 3D). Aunque cada vez esto queda restringido a menos casos. Basta con citar que se implementan motores videojuegos directamente con Canvas (p. ej: PlayN de Google).
- Demasiados lenguajes de programación para back-end y front-end (que ya de por sí son tres: HTML/CSS/Javascript).
Un ejemplo práctico
Vamos a implementar un ejemplo sencillo tratando de reutilizar una misma interfaz (front-end) HTML/CSS/Javascript con diferentes implementaciones del back-end (una mini-lógica). La idea es que se podría cambiar el back-end sin tocar ninguna línea del front-end.
Por otra parte, y aplicando el principio de diseño SOLID de la inversión de dependencias, separaremos front-end de back-end mediante una abstracción, que actuará a modo de contrato y que deberá ser llamada por el front-end e implementada por los diferentes back-ends.
//interfaz back-end
/* suma dos numeros (dos primeros parámetros). El resultado se
pasará como parámetro a la función de callback proporcionada
desde el front-end */
sum = function (int, int, callback )
/* obtiene un listado de nombres de frutas que, una vez "calculado",
será pasado como parámetro a la función de callback proporcionada
desde el front-end */
fruits = function ( callback )
La arquitectura se resume en la siguiente imagen:

Antes de continuar una pregunta: ¿Por qué no devolver el resultado como valor de retorno de las funciones? Se puede hacer sin problema, pero este diseño facilita que se puedan hacer llamadas asíncronas. Imaginemos que fruits() tarda cierto tiempo en calcularse, por lo que el back-end lanza un hilo de cálculo en segundo plano para no bloquear la interacción con el usuario, o que se conecta asíncronamente a un servidor remoto. Este diseño permite que cuando termine el proceso en segundo plano, éste llame de vuelta al front-end y le pase los resultados.
El front-end
El front-end consiste en un fichero HTML, que emplea una hoja de estilos CSS pequeña, junto con un Javascript sencillo a modo de controlador (controller.js).
index.html
<html>
<head>
<link rel="stylesheet" href="style.css" />
<script type="text/javascript" src="jquery-1.9.1.min.js"></script>
<!--
BACKEND CONFIGURATION
You can also use the same backend file (e.g.: backend.js)
and replace its real contents in order to avoid modifying
index.html to change the backend implementation
-->
<script type="text/javascript" src="backend-local-java.js"></script>
<!--<script type="text/javascript" src="backend-local-cpp.js"></script>-->
<!--<script type="text/javascript" src="backend-remote-server.js"></script>-->
<!--<script type="text/javascript" src="backend-local-js.js"></script>-->
<script type="text/javascript" src="controller.js"></script>
<head>
<body>
<div id="fruits">
<h1>Fruits</h1>
<ul id="fruitslist"></ul>
</div>
<div id="calculator">
<h1>Calculator</h1>
<label>A:</label>
<input id="aValue" type="text"/>
<label>B:</label>
<input id="bValue" type="text"/>
<input id="calculatebutton" type="button" value="calc"/>
<div id="result">Result: <span id="resultvalue"></span>
</div>
</div>
</body>
</html>
Las líneas que aparecen señaladas, muestran los diferentes back-end que se han implementado. La idea es que en un software real sólo habría una de esas cuatro líneas.
El controlador en Javascript (controller.js) se encarga de atender a los eventos de usuario, llamar al back-end a través de la interfaz abstracta (líneas resaltadas) y actualizar la interfaz de usuario con los resultados (modificando el HTML con JQuery).
//FRUITS CONTROLLER
function loaded(){
// call the back-end and provide
// a callback function to draw the results
backend.fruits(function(data){
for(var fruit in data){
$("#fruitslist").append("<li>"+data[fruit]+"</li>");
}
});
};
$(document).ready(function(){
// It seems that the backend object is not yet available on the
// body onload() or $(document).ready(). It seems that timers
// are started after the backend is injected.
setTimeout(loaded, 10);
});
//CALCULATOR CONTROLLER
//connect the 'calc' button listener
$(document).ready(function(){
$("#calculatebutton").click(function(){
var a = parseInt($("#aValue").val());
var b = parseInt($("#bValue").val());
// call the back-end and provide a callback
// function to draw results
backend.sum(a, b, function(result) {
$('#resultvalue').html(result);
});
});
}
);
Los diferentes back-end
Ahora se muestran los diferentes back-end: Java, C++, Servidor HTTP remoto (ej. PHP) y Javascript
backend Java con WebView JavaFX
Comenzamos por el fichero javascript que se debe incluir en el HTML para conectar el backend: backend-local-java.js
// nothing to do. The "backend" variable will be
// injected from the backend itself
Como se puede observar, no es necesario hacer nada, ya que la instanciación de la variable backend se hará en Java y desde allí se inyectará para que esté disponible en el código Javascript.
Veamos ahora la implementación en Java del back-end.
package es.uvigo.ei.sing.webviewdemo.backend;
import javafx.application.Platform;
import javafx.scene.web.WebEngine;
import es.uvigo.ei.sing.javafx.webview.JavascriptBridge;
public class BackendImpl extends JavascriptBridge {
public BackendImpl(final WebEngine engine, String varname) {
super(engine, varname);
}
public void fruits(final String callbackfunction){
new Thread(){
public void run() {
try {
Thread.sleep(1000);
Platform.runLater(new Runnable(){
@Override
public void run() {
call(callbackfunction,
new String[]{
"apple",
"orange",
"banana"});
}
});
} catch (InterruptedException e) { }
}
}.start();
}
public void sum(int a, int b,
final String callbackfunction){
call(callbackfunction, a+b);
}
}
La clase hereda de una clase de utilidad que hemos creado para facilitar dos cuestiones comunes:
- Reconectar el objeto de nuevo al contexto Javascript, ya que las variables se borran cuando se cambia de URL.
- Implementar un método call() para realizar los callback de vuelta hacia el front-end.
package es.uvigo.ei.sing.javafx.webview;
import java.util.LinkedList;
import javafx.beans.value.ChangeListener;
import javafx.beans.value.ObservableValue;
import javafx.concurrent.Worker.State;
import javafx.scene.web.WebEngine;
import netscape.javascript.JSObject;
/**
* A bridge intended to be a superclass of Java objects
* connected to the Javascript engine It is specifically
* designed to implement Java utility objects as a set of
* methods receiving a javascript callback function to be
* called-back with results. This is useful to make
* asynchronous designs from the Web UI tier to the bussiness
* logic tier.
*
* @author lipido
*/
public class JavascriptBridge {
protected WebEngine webEngine;
private String varname;
private InternalChangeListener changeListener;
protected JavascriptBridge(WebEngine engine,
final String varname){
this.webEngine = engine;
this.varname = varname;
//Listen to state changes and reconnect to web engine
this.changeListener = new InternalChangeListener();
webEngine.getLoadWorker().stateProperty().
addListener(changeListener);
}
private class InternalChangeListener implements
ChangeListener<State>{
public void changed(ObservableValue<? extends State> ov,
State oldState, State newState) {
if(newState == State.SUCCEEDED){
//reconnect the backend
connectToWebEngine();
}
}
private void connectToWebEngine() {
JSObject window = (JSObject)
webEngine.executeScript("window");
window.setMember(varname, JavascriptBridge.this);
}
};
protected void call(String callback, Object argument) {
webEngine.executeScript("___toEval = "+callback);
JSObject res = null;
JSObject window = (JSObject)
webEngine.executeScript("window");
if (argument instanceof String){
//it can parse as a json object
try{
res = (JSObject) webEngine.executeScript(
"eval("+argument.toString()+")"
);
window.call("___toEval", res);
}catch(Exception e){
// it is not parseable to a json object,
// so let the API to create the javascript
// object
window.call("___toEval", argument);
}
}else{
// it is not a json object, so let the
// API to create the javascript object
window.call("___toEval", argument);
}
}
}
Finalmente, una clase con el método de entrada main donde se crea el WebView de JavaFX, se le conecta una instancia de BackendImpl y se carga el index.html
package es.uvigo.ei.sing.webviewdemo;
import javafx.application.Application;
import javafx.scene.Scene;
import javafx.scene.layout.Region;
import javafx.scene.web.WebView;
import javafx.stage.Stage;
import es.uvigo.ei.sing.webviewdemo.backend.BackendImpl;
public class WebViewDemoJavaBackend extends Application {
@Override
public void start(Stage primaryStage) {
// create the JavaFX webview
final WebView webView = new WebView();
primaryStage.setScene(new Scene(new Region(){
{
getChildren().add(webView);
}
}, 340, 380));
primaryStage.setTitle("WebView with Java backend");
// connect the backend to the webview
new BackendImpl(webView.getEngine(), "backend");
// load index.html
webView.getEngine().load(
getClass().getResource("/index.html").
toExternalForm());
primaryStage.show();
}
public static void main(String[] args) {
launch(args);
}
}
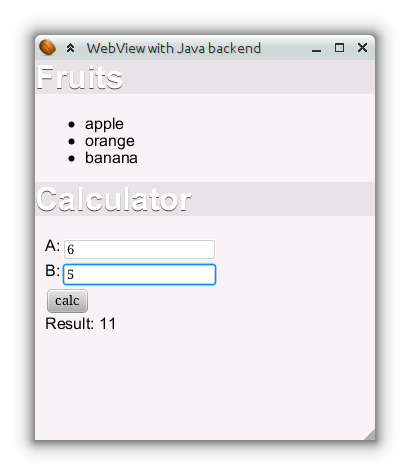
El resultado final es el siguiente:

Backend C++ con Webview Qt
Al igual que en el caso de Java, el fichero de backend javascript (backend-local-cpp.js) no contiene nada, puesto el objeto backend se inyectará desde el código C++ al arrancar el WebView.
// nothing to do. The "backend" variable will be
// injected from the backend itself
Continuamos por la implementación del Backend, con dos ficheros backend.h y backend.cpp, que constituyen la implementación de las funciones sum y fruits en C++, haciendo un callback hacia Javascript.
backend.h
#ifndef BACKEND_H
#define BACKEND_H
#include <qobject.h>
#include <QWebFrame>
#include <QString>
class Backend : public QObject
{
Q_OBJECT
private:
QString toFruits, varname;
QWebFrame * webview; //the engine
void call(QString callback, QString data);
public:
Backend(QWebFrame * webview, QString varname);
public slots:
void sum(int a, int b, QString callback);
void fruits(QString callback);
private slots:
void connectToWebEngine();
void doFruits();
};
#endif // BACKEND_H
backend.cpp
#include "backend.h"
#include <QThread>
Backend::Backend(QWebFrame * webframe, QString varname)
{
this->varname = varname;
this->webview = webframe;
connect(webframe, SIGNAL(javaScriptWindowObjectCleared()),
SLOT(connectToWebEngine()));
}
void Backend::connectToWebEngine(){
this->webview->addToJavaScriptWindowObject(this->varname, this);
}
void Backend::sum(int a, int b, QString callback){
this->call(callback, QString::number(a+b));
}
void Backend::fruits(QString callback2){
//we will run this inside a background thread
QThread * thread = new QThread();
this->toFruits = callback2;
connect(thread, SIGNAL(started()), this, SLOT(doFruits()));
thread->start();
}
void Backend::doFruits(){
QThread::sleep(2);
this->call(this->toFruits,
QString("['orange','apple','banana']"));
}
void Backend::call(QString call, QString data){
this->webview->evaluateJavaScript("__toEval = "+call);
QString s("__toEval("+data+")");
this->webview->evaluateJavaScript(s);
}
Al igual que en el caso de Java, es necesario reconectar el objeto C++ al WebView cada vez que se borran las variables Javascript. En este caso, no hemos creado una superclase con este comportamiento.
Finalmente, el fichero con el punto de entrada main donde se crea una ventana Html5ApplicationViewer, creada automáticamente con el asistente de Qt Creator cuando se crea un proyecto HTML 5.
main.cpp
#include <QApplication>
#include <QWebFrame>
#include "html5applicationviewer.h"
#include "backend.h"
int main(int argc, char *argv[])
{
QApplication app(argc, argv);
Html5ApplicationViewer window;
window.setOrientation(
Html5ApplicationViewer::ScreenOrientationAuto);
window.loadFile(QLatin1String("html/index.html"));
window.resize(340, 380);
window.setWindowTitle("Qt WebView with C++ Backend");
window.showExpanded();
new Backend(window.webFrame, "backend");
return app.exec();
}
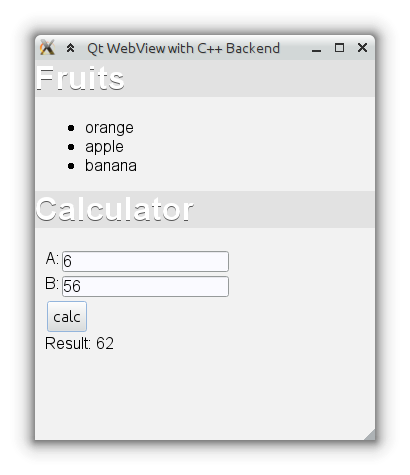
El resultado final es el siguiente:

Backend remoto HTTP (servidor en PHP)
Este ejemplo refleja un diseño más clásico. El WebView que es, en realidad, el navegador del usuario que se conecta con un servidor mediante AJAX para invocar las funciones sum y fruits. Aunque no tiene nada especial, se incluye aquí para demostrar que es un back-end a mayores del mismo front-end que permanece intacto.
En primer lugar, el fichero Javascript backend-remote-server.js que, esta vez sí, tiene contenido. Su misión es servir de intermediario para la comunicación HTTP con el back-end que se encuentra en un servidor remoto. Dicha comunicación se implementa con JQuery empleando la técnica AJAX.
backend-remote-server.js
// server implementation of backend
backend = {
sum: function(a, b, callback){
jQuery.ajax({
url: "http://localhost/sum.php?a="+a+"&b="+b,
success: function(data){ callback(data); }
});
},
fruits: function(callback){
jQuery.ajax({
url: "http://localhost/fruits.php",
success: function(data){ callback(eval(data)); }
});
}
};
El servidor en PHP implementa cada una de las funciones del back-end en un fichero PHP sencillo. Habitualmente lo que se encuentra en el servidor es un framework MVC con facilidades para servir peticiones al estilo API REST. Pero por sencillez se deja así.
sum.php
<?
echo $_GET["a"] + $_GET["b"];
?>
fruits.php
<?
echo "['banana', 'orange']";
?>
Back-end en Javascript
En este último ejemplo, el WebView vuelve a ser el navegador Implementar el Back-end en Javascript puede ser interesante, sobre todo en dos casos:
- Implementación de un prototipo del backend (mock). De esta forma, el diseñador de la interfaz puede simular las respuestas del back-end sin tenerlo disponible todavía.
- Conseguir que la aplicación sea totalmente portable, sin emplear ningún lenguaje de programación nativo. Sin embargo, si se desea acceder a funciones de más bajo nivel, sería necesario algo estilo PhoneGap (para funciones de smartphones) o conectar al lenguaje nativo como se ha visto en los ejemplos anteriores.
A continuación, se incluye la implementación del back-end en Javascript: fichero backend-local-js.js
// local javascript implementation of backend
backend = {
sum: function(a, b, callback){
return callback(a + b);
},
fruits: function(callback){
return callback(['orange', 'strawberry']);
}
};
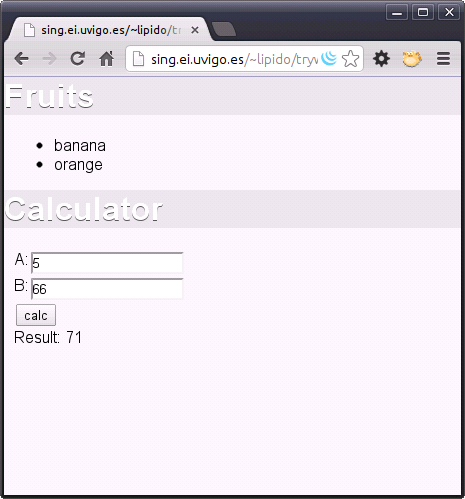
El resultado final es el siguiente:

Resumen
El conjunto de estándares más empleados en el desarrollo de las interfaces de usuario Web, formadas principalmente por HTML/CSS/Javascript está experimentando en los últimos años grandes avances. Tanto es así que se han exportado al desarrollo de aplicaciones en otros contextos, concretamente móviles y escritorio. Este post trata de demostrar que es posible, y relativamente sencillo, crear la interfaz de usuario de una aplicación de escritorio mediante estas tecnologías. Además, separando la lógica de negocio (back-end) de la interfaz de usuario (front-end) se pueden incluir verdaderos especialistas en la Web en proyectos de aplicaciones de escritorio.
Código fuente
Finalmente adjunto el código fuente.