Introduction¶
As the following image shows, SEDA uses the Input-Process-Output (IPO) model to process sequence files in FASTA format (https://en.wikipedia.org/wiki/FASTA_format).
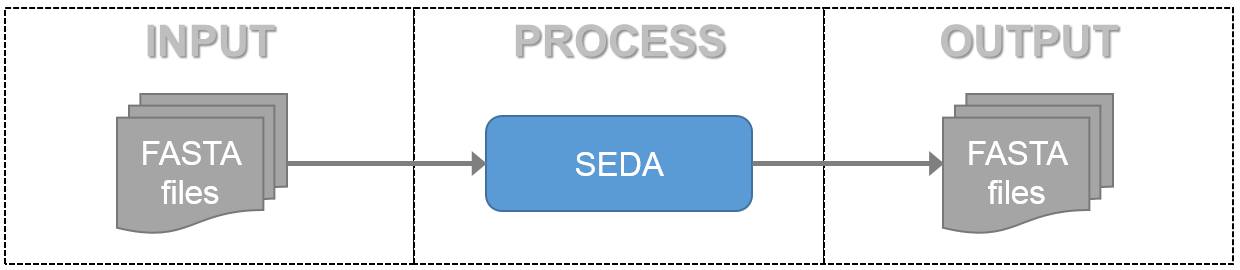
According to the FASTA format, each file may contain one or more sequences. Each sequence is composed by a header line which begins with ‘>’ and one or more lines containing the nucleotide or amino acid sequences represented using single-letter codes. The header of a sequence typically should give a name (unique identifier) for the sequence, and may also contain additional information (called description). The description is separated by a blank space from the sequence name/identifier. The following example shows a sequence in FASTA format.
>SEQUENCE_NAME_IDENTIFIER Description
ACTGACTGACTGACTGACTGACTGACTGACTGACTGACTGACTGACTG
ACTGACTGACTGACTGACTGACTG